Random Walk¶
As discussed, a random walk has a non-constant variance. Since is not constant, a random walk (even without drift) is not stationary. How might we go about isolating a stationary time series from a random walk? Detrending will remove any drift thereby stabilizing the mean, but it will not help with the non-constant variance. Instead, we rely on the process of differencing.
Differencing is defined as taking the difference between values. For example, the first difference of a random walk without drift is given by
Note that (starting our time series with as some arbitrary constant)
Thus, the first difference of a random walk without drift is white noise and hence stationary. What about a random walk with drift? Starting again with an arbitrary
Since is constant, is also constant. Similarly, the addition of does not change the covariance , so the first difference of a random walk with drift is also stationary.
Difference Stationary Process¶
For pure random walk processes, Eq.s (2) and (3) represent the limit of our analysis. However, very often we will encounter a difference stationary process defined again as
where in this case is a random walk process[1]. Taking the first difference, we have
If is stationary, the first difference must be as well:
and
Differencing to Differentiation¶
Finite Differences¶
Differencing is closely related to the discrete analog of differentiation. Assuming our time series originates from the continuous process with first derivative , the backward finite difference approximation to the derivative is
As we are assuming a constant sampling rate, we can treat as 1 in the unit of our time steps (seconds, days, years, etc.). By the same logic, we can approximate the second derivative using the backward second-order difference
Where as before we can reduce to by treating as 1[2].
Since the first derivative of a linear process is a constant, taking the first difference of a linear trend stationary process will result in a stationary process, though it may be very different than the series generated by detrending. By the same logic, taking the second difference will convert a quadratic trend into a stationary process.
Differencing Notation¶
Because differencing plays such a central role in time series analysis, there are specific notations designed to allow easier manipulation. The first difference is denoted by
Note the similarity to Eq. (10). The second difference is denoted by and resembles Eq. (11)
Higher order differences can be defined analogously, but in practice we will almost never need to go beyond the second difference.
Backshift Operator¶
The backshift operator, , is a valuable tool in time series analysis. While at first it may seem like we are introducing notation for its own sake, over the course of the book we will see that the backshift operator is an elegant and powerful way to manipulate time series.
The backshift operator changes a member of a series to the preceding value, i.e.:
Similarly, , and so on.
For completeness, we also define 's inverse as the forward-shift operator such that .
Differencing in Backshift Operator Notation¶
Combining Eq. (12) and Eq. (14), we can rewrite the first difference with unit time as
The second difference can be expressed as
Higher order differences are defined as .
Differencing vs. Detrending¶
While both detrending and differencing have their places, differencing is more commonly favored. Differencing has the major advantage that it is non-parametric, i.e. it does not rely on assuming any model (beyond a random walk) and parameters. In contrast, detrending assumes the existence of a linear (or higher-order) trend. Moreover, differencing a stationary series, while undesirable[3], will result in another stationary series, whereas detrending a stationary series will introduce the opposite trend.
Differencing more naturally extends to higher derivatives, for example using the second difference for constant acceleration processes. Detrending via quadratic fit lines makes very strong assumptions about the underlying model and is prone to overfitting.
In contrast, detrending provides a readily interpretable model of the overall trend that can be communicated to clients or sponsors. Detrending allows a clean explanation along the lines of “After removing a steady three unit per month increase, we see that...”, which is not possible with differencing. While differencing is more commonly the favored approach, ultimately the choice depends on your use case and intended audience.
Differencing S&P 500¶
Previously, we detrended the S&P 500 using a linear trend, resulting in Figure 1.
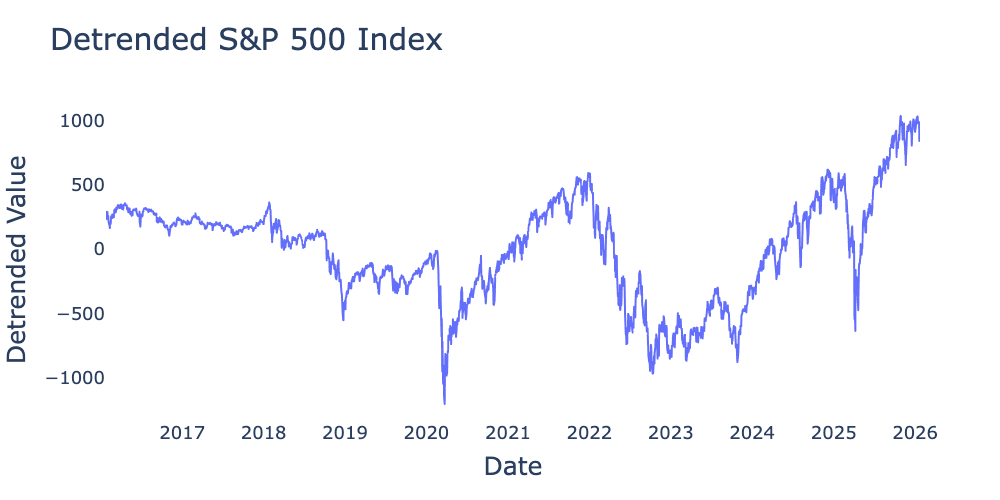
Figure 1:Detrended values of S&P 500 index for the 10-year period from January 2016 through January 2026 from Federal Reserve Bank of St. Louis detrended using .
What would happen if we instead take the first difference? pandas has a diff method accessed by df.diff(periods=1). Running the code
# Pandas uses periods=1 by default.
sp_500_diff = sp_500_df.diff().dropna()we can use the differenced time series to create Figure 2
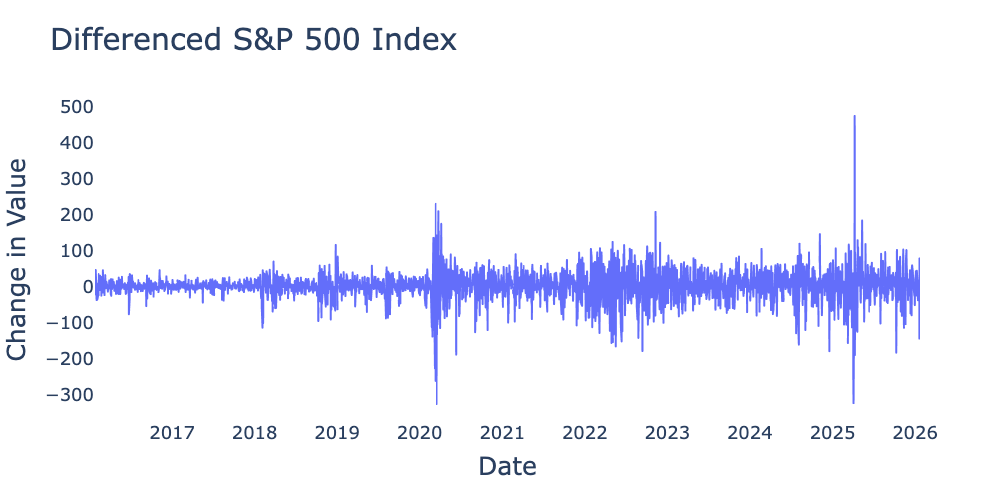
Figure 2:First difference of values of S&P 500 index for the 10-year period from January 2016 through January 2026 from Federal Reserve Bank of St. Louis.
Figure 2 appears more likely to be stationary than Figure 1, though I would caution against relying too heavily on pure visual inspection for either trends or overall stationarity. The mean of the differenced S&P 500 is 1.93, fairly close to the linear regression slope of 1.66. Figure 2 does appear to exhibit volatility clustering, which we will learn in subsequent chapters can be understood via the ARCH family of models. Nevertheless, it is reasonable to conclude that the S&P 500 roughly follows a random walk with drift of , making its first difference stationary white noise.
Autocorrelation of Random Walk¶
Before examining the autocorrelation, let’s work out what we expect the autocovariance of a random walk to look like. We’ve established that the autocovariance of a random walk is given by
Translating to autocorrelation is a bit tricky as a random walk’s variance is non-constant. Standard statistical packages still use the sample approximation for and
Even though Eq. (22) is only strictly valid for stationary time series, we can use it to approximate the autocorrelation for our case as well. Combining Eq.s (21) and (22) for a time series of length gives us
which represents a linear decay as increases.
Do the autocorrelation functions agree with our assessment that the S&P 500 is a random walk? Let’s look at them:
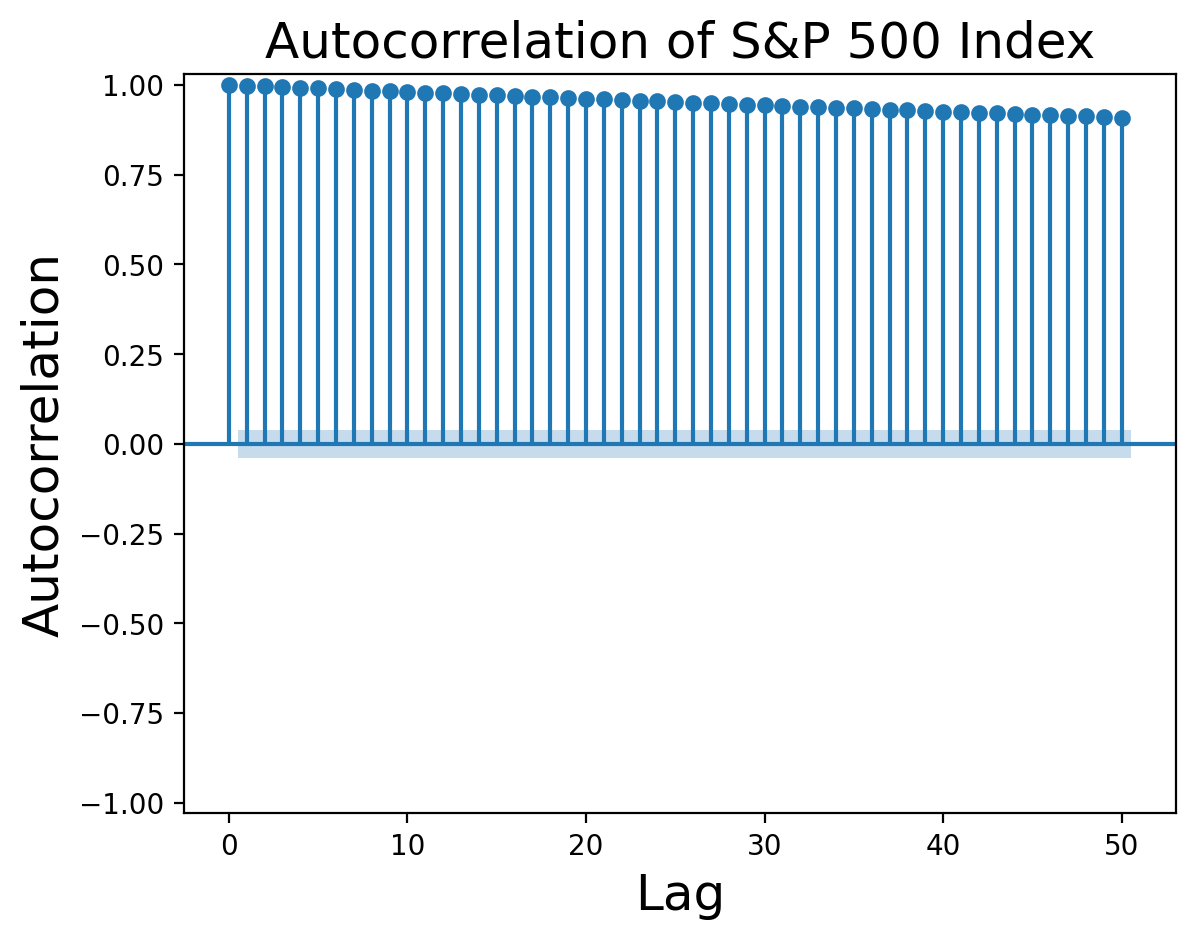
Figure 3:Autocorrelation function of S&P 500 returns from Federal Reserve Bank of St. Louis.
Figure 3 certainly looks like pure linear decay. What about the autocorrelation of the differenced series?
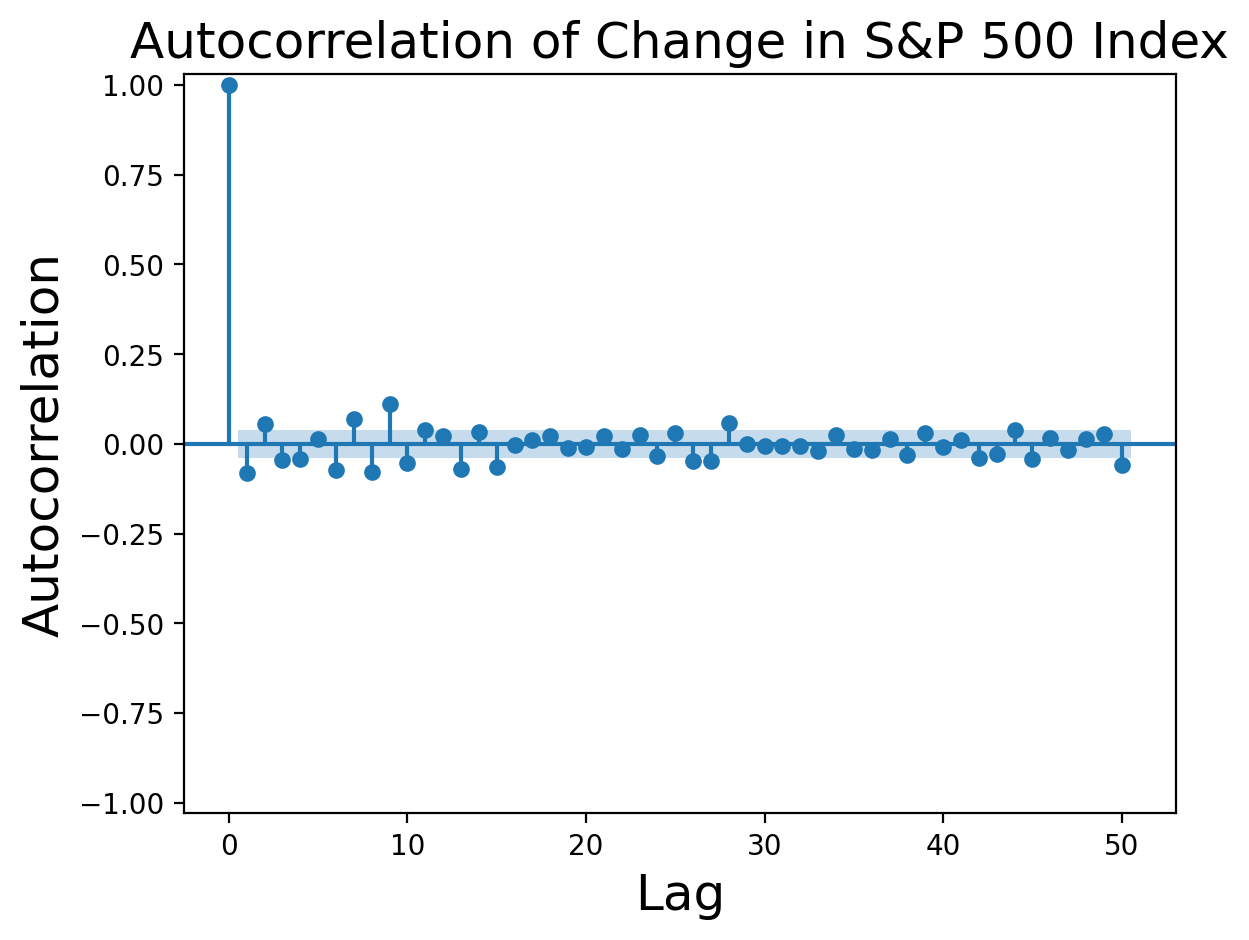
Figure 4:Autocorrelation function of first difference of S&P 500 returns from Federal Reserve Bank of St. Louis.
Multiple values before are significant beyond the level expected for pure white noise, indicating that our original process was probably not a pure random walk. Nevertheless, the autocorrelation values are small enough to say that a random walk is a reasonable first approximation to the S&P 500 returns.
We will discover other scenarios of difference stationary process where is not a simple random walk, but is a process possessing a unit root. We will defer discussion of these cases until after we have covered ARMA processes. For the time being, you can think of the concept of unit root as referring to random walks.
When we cover ARMA processes we will see that unnecessary differencing adds an additional moving average (MA) term and frequently results in non-invertible models.